

NVIDIA宣布推出NVIDIA Nemotron 3系列開源模型、資料與函式庫,透過透明、高效且開源的方式助AI產業發展,NVIDIA希冀透過持續釋出不斷進化的Nemotron開源模型,將A轉化為開放平台;Nemotron 3系列採用混合專家(MoE)架構,可協助開發者打造大規模代理型系統,並具備所需的透明度與效率。
Nemotron 3系列模型將提供Nano(30B)、Super(100B)及Ultra(500B)三種參數規模,Nemotron Nano即日起釋出,Super及Ultra預計於2026年上半年釋出。埃森哲、益華電腦、CrowdStrike、Cursor、德勤、安永、Oracle Cloud
Infrastructure、Palantir、Perplexity、ServiceNow、西門子、新思科技及Zoom已經著手整合Nemotron系列模型並應用於製造、資安、軟體開發、媒體、通訊等AI工作流程。
透過混合專家架構提高效率、精度並重塑多代理AI
Nemotron 3系列模型採用MoE混合專家架構,意即透過將多個領域的功能整合在單一模型,於目標明確、高效的任務使用其中一部分,藉此實現滿足多重領域、高效率的AI體驗,使單一模型可提供多重代理,不須因應需求呼叫與重新載入不同的模型。
借助Nemotron 3系列模型,提供開發者依據工作負載挑選合適的模型作為基礎,自數十個代理擴展至數百個代理,並提供更快、更準確的長期推論,處理複雜的工作流程。
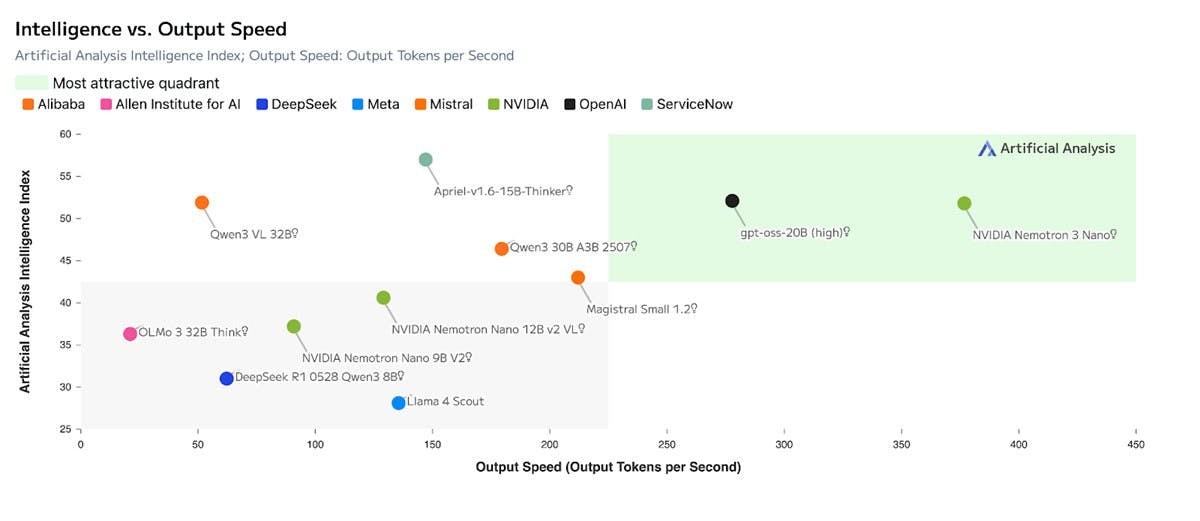
較前身大幅降低推論成本且領先同級的Nemotron 3 Nano
其中Nemotron 3 Nano是強調運算成本效益的模型,本身具有300B參數,於目標明確、高效任務使用最多3B參數,是針對軟體除錯、內容摘要、AI助理工作流程、資訊檢索等任務提供低推論成本最佳化的模型,並具備效率即可擴展性。
相較Nemotron 2 Nano,MoE架構可將詞元輸送量提高4倍,並將推論詞元生成量降低至60%,大幅減少推論成本,同時透過100萬詞元情境窗口,可記住更多內容提高精度,並有效連接常流程、多步驟任務的資訊。
擅長處理多代理協作的Nemotron 3 Super與具深度研究及策略規劃的Nemotron 3 Ultra
更為進階的Nemotron 3 Super與Nemotron 3 Ultra是透過NVIDIA Blackwell的4bit NVFP4作為訓練格式,以顯著降低記憶體需求的高效率方式進行訓練,展現更大型模型在既有基礎設施完成訓練、準確度也不遜於更高精度的格式。
Nemotron 3 Super具備100B參數,在專注特定任務時使用最多10B活躍參數,鎖定需要多個代理協作、低延遲完成複雜任務的應用;Nemotron 3 Ultra為大型推論引擎,具備500B參數以及每詞元最多50B活躍參數,適用於需要深度研究與策略規劃的AI工作流程。
完整訓練資料集與強化學習函式庫協助開發者打造專業AI代理
作為開放策略的一環,NVIDIA同步在GitHub與Hugging Face釋出訓練資料集與強化學習函式庫,開發者能藉此打造專業AI代理。
其中包括具備3兆詞元的全新Nemotron預訓練、後訓練與強化學習資料庫,可作為推論、程式碼與多步驟工作流程範例,並建構具強大功能與領域專業化的代理;此外Nemotron Agentic Safety Dataset則提供真實世界的遙測資料,協助開發團隊評估與強化複雜代理系統的安全性。
同時NVIDIA還公布NeMo Gym以及NeMo RL開源函式庫,包含Nemotron模型所需的訓練環境與訓練基礎,以及推出用於驗證模型安全與效能的NeMo Evaluator工具。
Nemotron 3可支援包括LM Studio、llama.cpp、 SGLang以及 vLLM。同時Prime Intellect以及Unsloth也著手 NeMo Gym的即用型訓練環境直接整合至工作流程,使開發者更快、更容易取得強化學習訓練資源。

您可能也會喜歡

批評者痛批「墮落唐納」,因 Epstein 線人聲稱遭死亡威脅

Solana 價格預測:SOL 和 BNB 交易者轉向 DeepSnitch AI 100 倍預售於 2026 年
