

Извлечение семантики открытого набора: конвейер Grounded-SAM, CLIP и DINOv2
Таблица ссылок
Резюме и 1 Введение
-
Связанные работы
2.1. Навигация с использованием зрения и языка
2.2. Семантическое понимание сцены и сегментация экземпляров
2.3. 3D реконструкция сцены
-
Методология
3.1. Сбор данных
3.2. Семантическая информация открытого набора из изображений
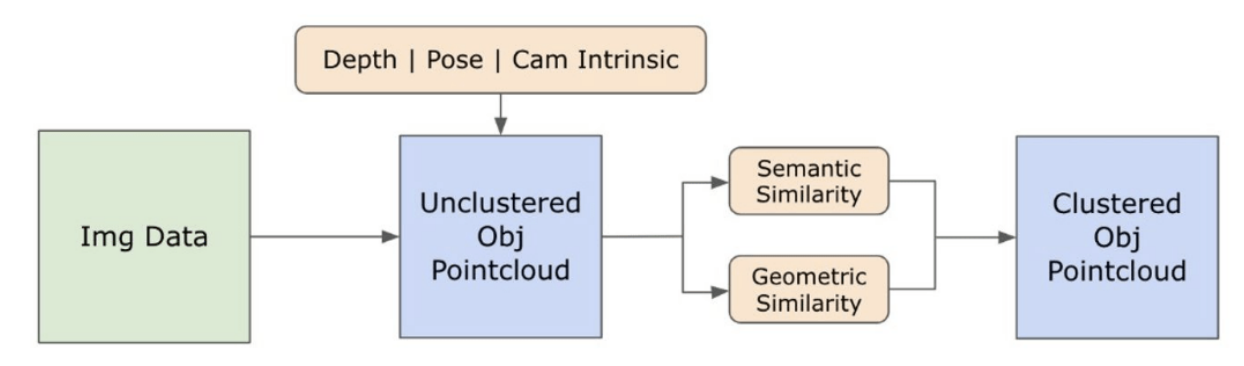
3.3. Создание 3D-представления открытого набора
3.4. Навигация на основе языка
-
Эксперименты
4.1. Количественная оценка
4.2. Качественные результаты
-
Заключение и будущая работа, заявление о раскрытии информации и ссылки
3.2. Семантическая информация открытого набора из изображений
\ 3.2.1. Обнаружение семантических масок открытого набора и масок экземпляров
\ Недавно выпущенная модель Segment Anything (SAM) [21] приобрела значительную популярность среди исследователей и промышленных практиков благодаря своим передовым возможностям сегментации. Однако SAM имеет тенденцию создавать чрезмерное количество масок сегментации для одного и того же объекта. Мы используем модель Grounded-SAM [32] для нашей методологии, чтобы решить эту проблему. Этот процесс включает создание набора масок в три этапа, как показано на рисунке 2. Изначально набор текстовых меток создается с использованием модели Recognizing Anything (RAM) [33]. Затем создаются ограничивающие рамки, соответствующие этим меткам, с использованием модели Grounding DINO [25]. Изображение и ограничивающие рамки затем вводятся в SAM для создания агностических к классам масок сегментации для объектов, видимых на изображении. Мы предоставляем подробное объяснение этого подхода ниже, который эффективно смягчает проблему чрезмерной сегментации путем включения семантических данных из RAM и Grounding-DINO.
\ Модель RAM [33] обрабатывает входное RGB-изображение для создания семантической маркировки объекта, обнаруженного на изображении. Это надежная базовая модель для тегирования изображений, демонстрирующая замечательную способность к нулевому обучению в точном определении различных общих категорий. Выход этой модели связывает каждое входное изображение с набором меток, которые описывают категории объектов на изображении. Процесс начинается с доступа к входному изображению и преобразования его в цветовое пространство RGB, затем изменения размера для соответствия требованиям входных данных модели и, наконец, преобразования его в тензор, делая его совместимым с анализом модели. После этого модель RAM генерирует метки или теги, которые описывают различные объекты или особенности, присутствующие на изображении. Для уточнения сгенерированных меток применяется процесс фильтрации, который включает удаление нежелательных классов из этих меток. В частности, отбрасываются нерелевантные теги, такие как "стена", "пол", "потолок" и "офис", вместе с другими предопределенными классами, считающимися ненужными для контекста исследования. Кроме того, этот этап позволяет дополнить набор меток любыми необходимыми классами, которые изначально не были обнаружены моделью RAM. Наконец, вся соответствующая информация агрегируется в структурированный формат. В частности, каждое изображение каталогизируется в словаре img_dict, который записывает путь изображения вместе с набором сгенерированных меток, обеспечивая тем самым доступное хранилище данных для последующего анализа.
\ После тегирования входного изображения сгенерированными метками рабочий процесс продолжается вызовом модели Grounding DINO [25]. Эта модель специализируется на привязке текстовых фраз к конкретным областям внутри изображения, эффективно очерчивая целевые объекты с помощью ограничивающих рамок. Этот процесс идентифицирует и пространственно локализует объекты внутри изображения, закладывая основу для более детального анализа. После идентификации и локализации объектов с помощью ограничивающих рамок используется модель Segment Anything (SAM) [21]. Основная функция модели SAM заключается в создании масок сегментации для объектов внутри этих ограничивающих рамок. Таким образом, SAM изолирует отдельные объекты, позволяя проводить более детальный и специфичный для объекта анализ, эффективно отделяя объекты от их фона и друг от друга на изображении.
\ На этом этапе экземпляры объектов были идентифицированы, локализованы и изолированы. Каждый объект идентифицируется с различными деталями, включая координаты ограничивающей рамки, описательный термин для объекта, вероятность или оценку достоверности существования объекта, выраженную в логитах, и маску сегментации. Кроме того, каждый объект связан с функциями встраивания CLIP и DINOv2, подробности которых изложены в следующем подразделе.
\ 3.2.2. Извлечение семантического встраивания
\ Для улучшения нашего понимания семантических аспектов экземпляров объектов, которые были сегментированы и замаскированы в наших изображениях, мы используем две модели, CLIP [9] и DINOv2 [10], для получения представлений признаков из обрезанных изображений каждого объекта. Модель, обученная исключительно с помощью CLIP, достигает надежного семантического понимания изображений, но не может различать глубину и сложные детали внутри этих изображений. С другой стороны, DINOv2 демонстрирует превосходную производительность в восприятии глубины и отлично справляется с идентификацией нюансированных отношений на уровне пикселей между изображениями. Как самоконтролируемый Vision Transformer, DINOv2 может извлекать нюансированные детали признаков без опоры на аннотированные данные, что делает его особенно эффективным при идентификации пространственных отношений и иерархий внутри изображений. Например, в то время как модель CLIP может испытывать трудности с различением двух стульев разных цветов, таких как красный и зеленый, возможности DINOv2 позволяют четко проводить такие различия. В заключение, эти модели фиксируют как семантические, так и визуальные особенности объектов, которые позже используются для сравнения сходства в 3D-пространстве.
\ 
\ Набор шагов предварительной обработки реализуется для обработки изображений с моделью DINOv2. Они включают изменение размера, центральную обрезку, преобразование изображения в тензор и нормализацию обрезанных изображений, очерченных ограничивающими рамками. Обработанное изображение затем подается в модель DINOv2 вместе с метками, идентифицированными моделью RAM, для создания функций встраивания DINOv2. С другой стороны, при работе с моделью CLIP шаг предварительной обработки включает преобразование обрезанного изображения в формат тензора, совместимый с CLIP, с последующим вычислением функций встраивания. Эти встраивания критически важны, поскольку они инкапсулируют визуальные и семантические атрибуты объектов, которые необходимы для всестороннего понимания объектов на сцене. Эти встраивания подвергаются нормализации на основе их L2-нормы, которая корректирует вектор признаков до стандартизированной единичной длины. Этот шаг нормализации обеспечивает последовательные и справедливые сравнения между различными изображениями.
\ На этапе реализации этой стадии мы перебираем каждое изображение в наших данных и выполняем следующие процедуры:
\ (1) Изображение обрезается до области интереса с использованием координат ограничивающей рамки, предоставленных моделью Grounding DINO, изолируя объект для детального анализа.
\ (2) Генерируем встраивания DINOv2 и CLIP для обрезанного изображения.
\ (3) Наконец, встраивания сохраняются вместе с масками из предыдущего раздела.
\ С завершением этих шагов мы теперь обладаем детальными представлениями признаков для каждого объекта, обогащая наш набор данных для дальнейшего анализа и применения.
\
:::info Авторы:
(1) Лакш Нанвани, Международный институт информационных технологий, Хайдарабад, Индия; этот автор внес равный вклад в эту работу;
(2) Кумарадитья Гупта, Международный институт информационных технологий, Хайдарабад, Индия;
(3) Адитья Матур, Международный институт информационных технологий, Хайдарабад, Индия; этот автор внес равный вклад в эту работу;
(4) Свайам Агравал, Международный институт информационных технологий, Хайдарабад, Индия;
(5) А.Х. Абдул Хафез, Университет Хасана Кальонджу, Шахинбей, Газиантеп, Турция;
(6) К. Мадхава Кришна, Международный институт информационных технологий, Хайдарабад, Индия.
:::
:::info Эта статья доступна на arxiv под лицензией CC by-SA 4.0 Deed (Attribution-Sharealike 4.0 International).
:::
\
Вам также может быть интересно

Ключевые уровни проверены на фоне стагнации Биткоина

SHIB в застое, в то время как DeepSnitch AI приближается к сбору 1 млн $
