Matting Robust Ghidat de Mască: Gestionarea Intrărilor Zgomotoase și Versatilitatea Obiectelor
Tabel de Link-uri
Rezumat și 1. Introducere
-
Lucrări Conexe
-
MaGGIe
3.1. Matting Eficient Ghidat cu Mască pentru Instanțe
3.2. Consistență Temporală Feature-Matte
-
Seturi de Date pentru Matting de Instanțe
4.1. Matting de Instanțe pentru Imagini și 4.2. Matting de Instanțe pentru Video
-
Experimente
5.1. Preantrenare pe date de imagini
5.2. Antrenare pe date video
-
Discuții și Referințe
\ Material Suplimentar
-
Detalii de arhitectură
-
Matting de imagini
8.1. Generarea și pregătirea seturilor de date
8.2. Detalii de antrenare
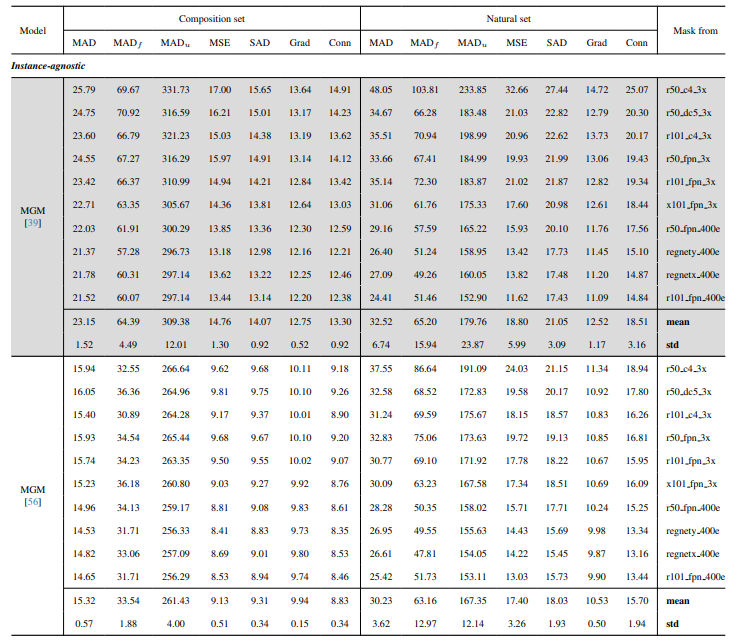
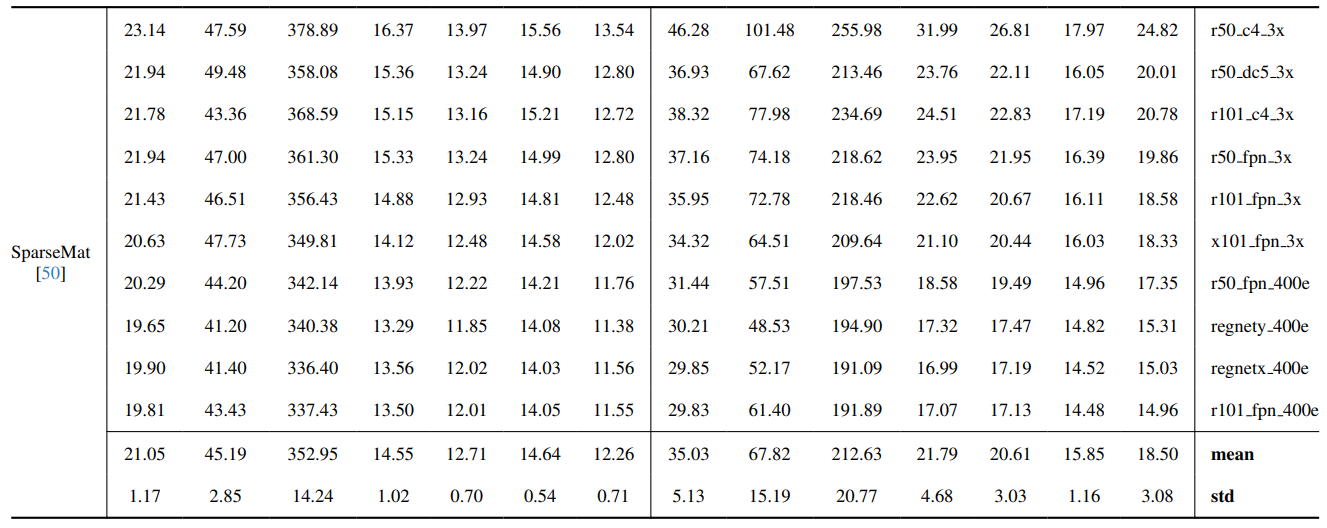
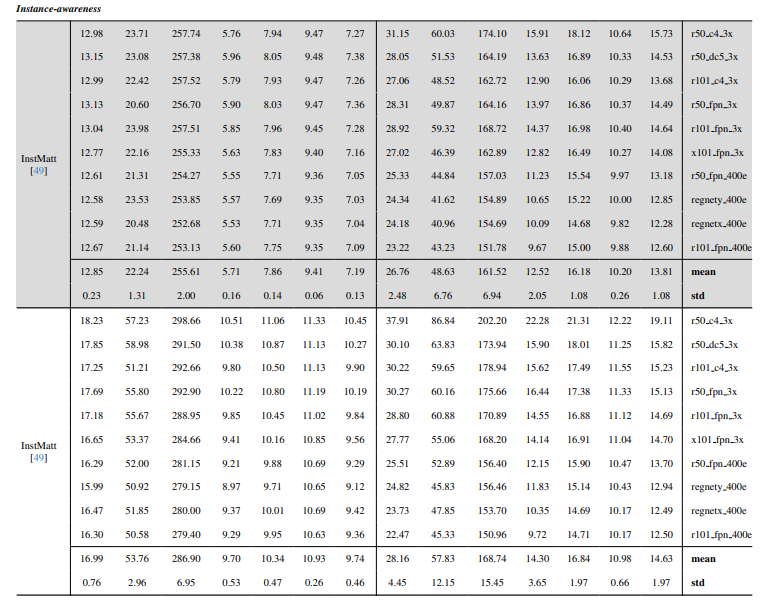
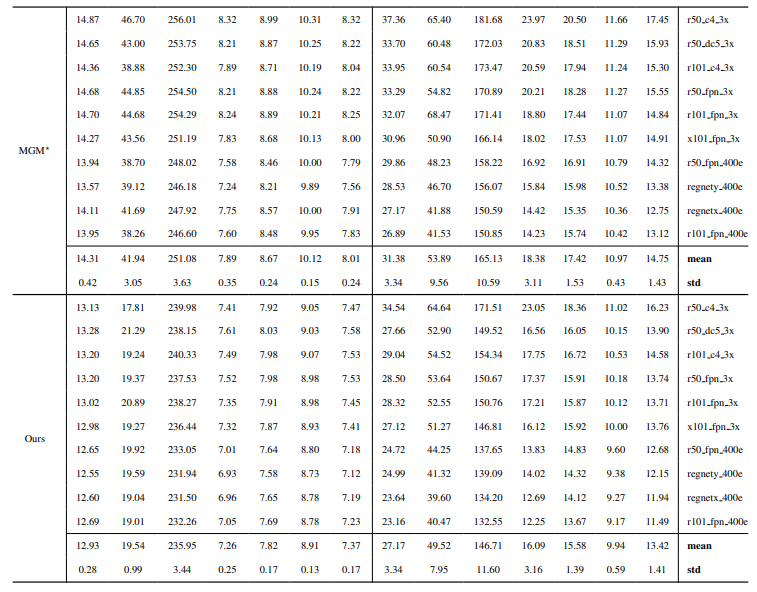
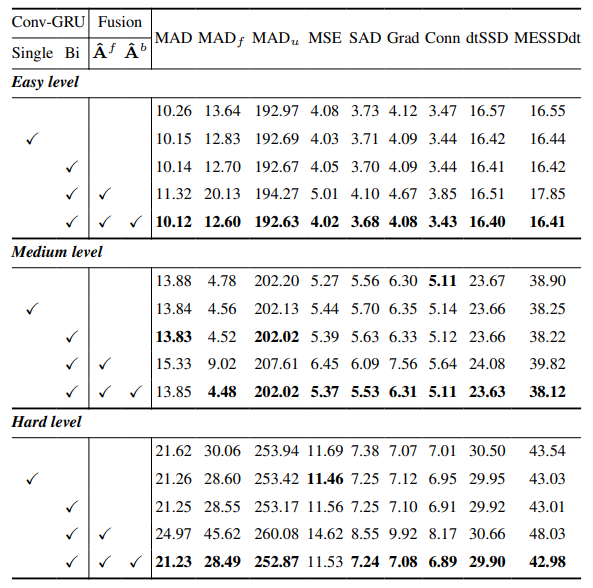
8.3. Detalii cantitative
8.4. Mai multe rezultate calitative pe imagini naturale
-
Matting video
9.1. Generarea setului de date
9.2. Detalii de antrenare
9.3. Detalii cantitative
9.4. Mai multe rezultate calitative
8.4. Mai multe rezultate calitative pe imagini naturale
Fig. 13 prezintă performanța modelului nostru în scenarii dificile, în special în redarea exactă a regiunilor de păr. Cadrul nostru depășește constant MGM⋆ în păstrarea detaliilor, mai ales în interacțiunile complexe între instanțe. În comparație cu InstMatt, modelul nostru prezintă o separare superioară a instanțelor și acuratețe a detaliilor în regiunile ambigue.
\ Fig. 14 și Fig. 15 ilustrează performanța modelului nostru și a lucrărilor anterioare în cazuri extreme care implică mai multe instanțe. În timp ce MGM⋆ se confruntă cu zgomot și acuratețe în scenarii dense de instanțe, modelul nostru menține o precizie ridicată. InstMatt, fără date suplimentare de antrenare, prezintă limitări în aceste contexte complexe.
\ Robustețea abordării noastre ghidate cu mască este demonstrată în continuare în Fig. 16. Aici, evidențiem provocările cu care se confruntă variantele MGM și SparseMat în predicția părților lipsă din intrările de mască, pe care modelul nostru le rezolvă. Cu toate acestea, este important de menționat că modelul nostru nu este conceput ca o rețea de segmentare a instanțelor umane. Așa cum se arată în Fig. 17, cadrul nostru respectă ghidajul de intrare, asigurând predicția precisă a alpha matte chiar și cu mai multe instanțe în aceeași mască.
\ În final, Fig. 12 și Fig. 11 subliniază capacitățile de generalizare ale modelului nostru. Modelul extrage cu acuratețe atât subiecții umani, cât și alte obiecte din fundaluri, demonstrând versatilitatea sa în diverse scenarii și tipuri de obiecte.
\ Toate exemplele sunt imagini de pe Internet fără ground-truth, iar masca de la r101fpn400e este folosită ca ghidaj.
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\
:::info Autori:
(1) Chuong Huynh, University of Maryland, College Park ([email protected]);
(2) Seoung Wug Oh, Adobe Research (seoh,[email protected]);
(3) Abhinav Shrivastava, University of Maryland, College Park ([email protected]);
(4) Joon-Young Lee, Adobe Research ([email protected]).
:::
:::info Această lucrare este disponibilă pe arxiv sub licență CC by 4.0 Deed (Attribution 4.0 International).
:::
\


Poate îți place și

Creditorii legați de Coreea de Nord vizează fondurile înghețate Kelp DAO

Todd Blanche uimește cu admiterea „drăgălașă" că afirmațiile lui Trump privind „exonerarea" sunt false